How Does ChatGPT Work?

Ready to uncover the magic behind ChatGPT? This guide walks you through the breakthroughs, data, and algorithms that drive its AI, from foundational concepts to advanced techniques, while making it easy to follow for every reader. Start with Why is ChatGPT Considered AI?, or jump straight to explore Key Advancements That Led to ChatGPT, or How ChatGPT Works - Part 1.
Why is ChatGPT Considered AI?
The term Artificial Intelligence (AI) is often associated with, Hollywood movies, machines taking over the world. But what exactly does it mean for something to be considered AI? In 1956 John McCarthy, the mind behind the term, defined AI as "the science and engineering of making intelligent machines", in other words AI aims to mimic human thought processes like learning, reasoning, and problem-solving.
At that time, these AI pioneers experienced what's known as an AI summer, a time of increased interest and investment. There were a lot of breakthroughs and discoveries, which got people really excited about what computers could do.
For example, in 1957, Alex Bernstein developed the first-ever computer chess program. While revolutionary, its capabilities were limited, it took around 8 minutes to calculate a move and could be defeated by novice players. Nevertheless, this marked a milestone in the history of AI, as they could simulate human-like thought processes. It showcased a form of Narrow AI (NAI), a subset of AI, designed to perform a specific task, such as playing chess.
The excitement faded during the 1970s, leading to what's known as an AI winter. Funding and interest decreased as AI couldn't meet the high expectations, largely due to the limitations of the technology at the time.
In the 1990s, when technology got better, people started getting interested in AI again. This led to a historic achievement in 1997 when IBM's Deep Blue, another chess program, defeated the reigning world chess champion, Garry Kasparov, demonstrating the potential of AI systems to compete with and even surpass humans in specific tasks.
As technology continued to advance, interest in areas such as machine learning grew rapidly. This era witnessed the emergence of an early form of Generative AI (GAI), a model known as a Markov chain, named after the mathematician Andrey Markov. It was used for the autocomplete function in SMS apps to predict the next "most common" word based on preceding words. However, these models have limitations, they can only look back a few words so often lack context.
Fast forward to 2022, the release of ChatGPT 3.5 marked another milestone in the history of AI. Unlike the early autocomplete function, ChatGPT uses a type of neural network (NN) which enables it to keep track of context. But ultimately, it's still just predicating “what comes next” based on the predefined parameters of its model. So just like the early AI chess playing program, ChatGPT is considered 'Narrow AI,' since it can only do one thing: generate text. But as it can generate new content, it also gets classed in a subset of narrow AI known as Generative AI, more specifically a Large Language Model (LLM).
LLMs were created as a subset of Generative AI to specialize in various natural language processing tasks, such as text completion, translation, summarization, and answering questions, among others.
So, when we talk about AI, we're not just talking about Hollywood movies. We're talking about real breakthroughs in technology that are shaping the way we live. Now, if machines ever get as smart as humans in lots of different things, we'd call that Artificial General Intelligence (AGI). And if a machine becomes even smarter than humans in everything, that's Artificial Superintelligence (ASI).
The Psychological Impact of LLMs
Even though chatbots like ChatGPT and other LLMs operate by predicting the next most probable word in a sentence, their impact on users can be deeply psychological. When designed with a specific persona, these AI models can create the illusion of genuine conversation, emotional understanding, and even companionship, leading to significant effects on users' thoughts and feelings.
LLMs do not think, feel, or comprehend in the way humans do. They rely purely on statistical patterns derived from vast datasets to generate responses. However, because their outputs mimic human conversation so well, users often project emotions and even consciousness onto them. This can lead to emotional attachment or altered perceptions of AI capabilities.
One striking historical comparison is with ELIZA, an early chatbot created in the 1960s by Joseph Weizenbaum. ELIZA operated on simple pattern-matching techniques, primarily rephrasing users' inputs as questions (e.g., "I feel sad" might trigger "Why do you feel sad?"). Despite its rudimentary design, users reported feeling heard and understood, some even believing ELIZA had a form of intelligence. Weizenbaum himself was surprised at how easily people formed emotional connections with a machine.
Unlike ELIZA, today's LLMs generate much more sophisticated, context-aware, and emotionally nuanced responses. If given a persona, they can mimic specific tones, personalities, or even roles (such as a supportive friend). There's a growing number of persona websites which allow users to create their own chatbot characters. These platforms are incredibly popular, receiving tens of millions of direct visits per month. Notably, around 50% of the traffic on these sites comes from users aged 18 to 24, and about 25% from those aged 25 to 34, underscoring how appealing these personalized, human-like interactions are, especially among younger audiences.
But most people use chatbots for a variety of everyday tasks, including answering questions, getting recommendations, and assisting with work or study. Many rely on them for quick access to information, whether it's looking up facts, summarizing articles, or even generating creative content like stories or code.
Key Advancements That Led to ChatGPT
In November 2022 a blog post from OpenAI casually introduced ChatGPT. It was supposed to be a “research preview”, instead it went viral and marked the moment Generative AI became mainstream. While ChatGPT may have stormed onto the global stage seemingly out of nowhere, its development was far from instantaneous. It's the result of years of advancements. To help you understand how ChatGPT works, first consider these three factors that contributed to its development:
Large-Scale Datasets
For ChatGPT to make accurate predictions, it needs a lot of data. The more data it has, the better it can learn and perform. However, the model's accuracy also depends on the quality of the data. As the saying goes, "Garbage in, garbage out." That's why entire companies have been created to develop vast, high-quality datasets specifically for AI.
These companies (including OpenAI) use web crawling and data-scraping techniques to gather massive datasets from all sorts of online sources. Social media platforms like Reddit and Twitter, provide huge amounts of user-generated content. This data, often referred to as "conversation data," is perfect for training LLMs to understand how people talk to each other. While websites like Wikipedia provide a wide range of topics which is perfect for training the LLM so it can respond to diverse questions. However, Wikipedia makes up only about 3% of the dataset. To train a LLM the size of ChatGPT you need a lot more data. Some datasets contain billions of words.
Supercomputing
The creation of ChatGPT was made possible by significant advancements in supercomputing. Supercomputing refers to the use of extremely powerful computers to perform complex calculations at high speeds.
When you interact with ChatGPT, your message is first processed by the processor (CPU) and then sent to the GPUs, where it undergoes a series of complex mathematical operations. These operations involve performing billions of matrix multiplications and activations in a neural network, allowing the model to analyze the context of your input and generate a relevant response. The processed results are then sent back to the CPU, which returns the response to you. This heavy reliance on GPUs, known for their ability to handle massive parallel computations efficiently, is what enables large language models (LLMs) to function effectively.
Improvements in system management have also made it possible to scale up the infrastructure and train AI models on an unprecedented scale.
OpenAI, in collaboration with partners Microsoft and NVIDIA, built a supercomputing setup on Azure. This setup uses thousands of NVIDIA GPUs connected by high-speed networks like NVIDIA Quantum InfiniBand, providing the computational power needed to train and run ChatGPT.
While ChatGPT requires massive supercomputers to train and to serve millions of users simultaneously, breakthroughs have made it possible to run smaller AI chatbots directly on personal devices (laptops, smartphones etc). A locally running chatbot only needs to handle a single user, allowing it to run on much less powerful hardware.
This is thanks to model optimization. Researchers use techniques like quantization (shrinking AI models while keeping accuracy), distillation (training smaller models to mimic large ones), and hardware acceleration (using specialized chips like Apple's Neural Engine or NVIDIA Tensor Cores). These improvements reduce the size and power needs of AI, making it possible to run offline chatbots without the cloud.
This trend means AI will become cheaper and private, allowing users to chat with AI assistants anywhere, without relying needing the internet.
Scientific Research & Open Source
In 2017, a group of eight Google researchers made a groundbreaking discovery: the Transformer Architecture. This innovation transformed Natural Language Processing (NLP) by introducing "self-attention". Rather than analyzing words one by one, computers could now understand language as a whole, drastically improving processing speed and accuracy. The researchers shared their findings in the paper "Attention Is All You Need," releasing it as open source to the AI community. This opened the door for other companies to develop a range of applications and models, including ChatGPT, and started the era of generative AI.
How ChatGPT Works - Part 1
As the name suggests, ChatGPT operates using the GPT (Generative Pre-trained Transformer) architecture. It works by predicting the next word in a sentence through a method called autoregressive language modelling. This prediction is made possible by a neural network (the transformer model) and probability calculations. Before we dive into how the model works, let's first understand the training process.
Step 1: Data Collection
To start, OpenAI needs a big and diverse dataset (scientific researchers call it a corpus) that stays current, covers lots of different topics, writing styles, and languages. It needs to be really big to train a Large Language Model (LLM) effectively. The only place to find that much data is on the internet.
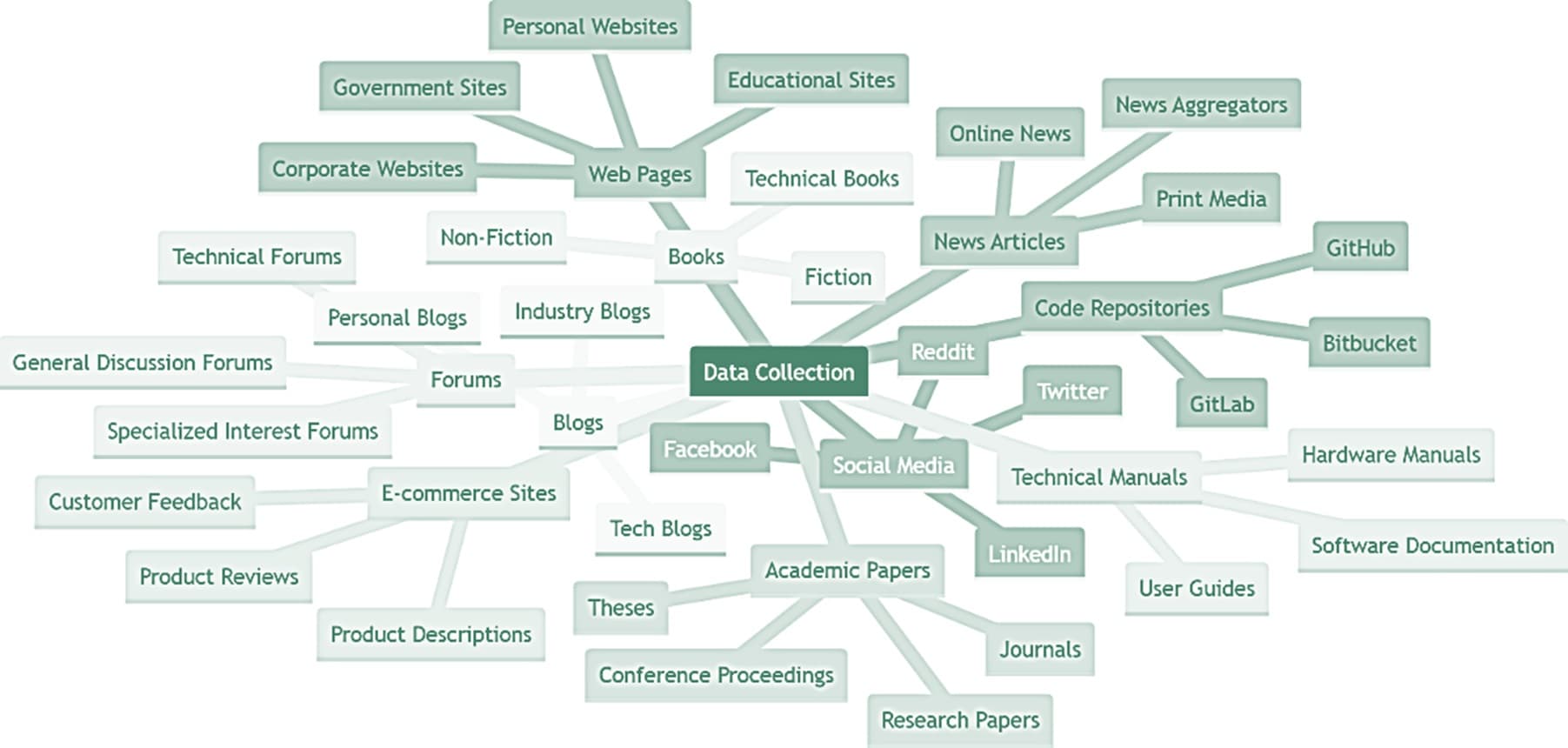
So OpenAI made a web crawler called GPTBot to gather data from the internet for their “corpus”. Now by default if you own a website that is not behind a paywall, the GPTBot might scrape your data for training ChatGPT. You can't remove any data that has already been scraped but to "opt-out" of future scraping, you can add a disallow entry to your websites robots.txt file to block the crawler.
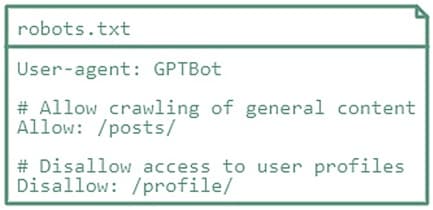
A robots.txt file is a simple text file placed on your website that gives instructions to web crawlers about which pages they can or can't access. To block GPTBot from your website, add these lines to your robots.txt file:

If you're okay with GPTBot accessing some parts but not others, customize the access permissions. For instance:
Remember though, if someone else scrapes your data and puts it on their site (and they haven't blocked GPTBot) or if someone copies your content into ChatGPT (and they haven't opted-out), your data could still contribute to training a model and this use of your data may not include references back to your website for OpenAI to know where the data originally came from.
Also, be aware that some third-party companies gather data from the internet and may sell their “corpus” (datasets) to OpenAI. This means your data might be used to train ChatGPT through this process.
If you want to protect your website from undesired scraping, consider deactivating the copy-and-paste functionality and implementing a bot management system (which can identify and block malicious bots attempting to scrape your content). Keep in mind that determined scrapers might still find methods to extract data.
Returning to the main point: once OpenAI have the "raw data," they proceed to clean it up using filters. Data from websites can contain irrelevant information, biases, sensitive data, and content that violates OpenAI's policies. Therefore, before it can be used to train ChatGPT, the dataset undergoes a cleaning process to remove the “noise”. Once the dataset has been cleaned, it's ready to be used in "Pre-Training."
Step 2: Pre-Training
At this point, OpenAI need to setup supercomputing neural network (NN) model configured with some “ground rules”. This model starts out as an empty template. Before the model can generate text, it goes through a process known as pre-training. Imagine this phase as the early years of a child, during which it learns language by being exposed to it. The pre-training process consists of three main phases.
Phase 1: Unsupervised Learning
The data collected earlier serves as the initial input for pre-training the NN. During this stage, the model first goes through a method known as unsupervised learning, meaning it learns without direct instructions. Instead, it's a type of machine learning. Machine learning has been a huge advantage because it means that we don't have to teach computers everything. You feed the machine tons of data, and it starts learning on its own. In this case, because ChatGPT uses a neural network with multiple layers we call it Deep Learning which is a subset of machine learning. The Deep Learning algorithm learns to find patterns and structure in the text and creates a vector representation of each word. An embedding vector is a list of numbers that approximate some point of meaning (we'll look more into vectors later).
Phase 2: Masked Language Model
Now after the initial phase, the model goes through something called Masked Language Model (MLM). During the MLM phase, a percentage of words in the text are randomly replaced with a special symbol, often denoted as [MASK]. The model's objective is to predict the original words based on the context provided by the surrounding words. It's like a game where the model learns to fill in the blanks. This helps the model get better at understanding how words fit together and what makes sense in different contexts.
Phase 3: Sentence Prediction
Following the MLM training, the model then moves on to the Next Sentence Prediction (NSP) phase. Here, it learns to figure out if one sentence logically follows another. The model looks at pairs of sentences and predicts whether the second one makes sense after the first. So, it's like the model's playing another game, this time to guess which sentence comes next. This helps the model get better at understanding how sentences fit together in a conversation.
MLM and NSP can be classed as unsupervised learning, where we don't rely on human-provided labels like we do in supervised learning. Instead, these methods use the data structure itself as a kind of built-in labeling system. We'll look into supervised learning next.
Step 3: Fine-Tuning
Pre-training gives ChatGPT a foundation in language and a broad knowledge base, this is known as a foundation model. But if you try using it, the responses might not always be accurate or make much sense. Fine-tuning refines its responses by training it on questions with the expected answers. There are different ways to fine-tune a LLM, but the process for ChatGPT involved Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). RLHF was first introduced in "Deep reinforcement learning from human preferences," a research paper published by OpenAI in 2017. This approach was fundamental to ChatGPT's success.
Phase 1: Supervised-Fine-Tuning
During the SFT phase, the pre-trained model is fine-tuned on a smaller refined dataset. A trainer gives the model a collection of example prompts (questions) along with their expected responses (answers), for example a prompt could be " Who was the first President of the United States? and expected response " George Washington". The model learns from these examples and adjusts its settings to respond to similar questions in the future. It's not just about storing questions/answers but learning the patterns behind them.
Phase 2: Reward Model
Once the SFT model is trained, it can be further refined using reinforcement learning techniques. In the second phase, the trainer provides a prompt (question) to the SFT model. The model then generates multiple responses to that prompt. These responses (answers) are evaluated by the trainer, who ranks them from best to worst based on their quality. This ranking data is then used to train a Reward Model (RM). The RM is created to provide feedback on the quality of the responses. If the response is good, it gives a positive score; if it's not as good, it gives a negative score.
Phase 3: Proximal Policy Optimization
In phase three, following the training of the SFT and RM models, the Proximal Policy Optimization (PPO) algorithm is used to refine the SFT model. The trainer provides a prompt (question) to the SFT model, the response is then evaluated by the RM to generate a reward based on how well they align with desired outcomes. This reward is then used by the PPO algorithm to update the SFT model's policy. Essentially, PPO optimises the SFT model, and the end result is known as a refined foundation model.
It's important to note that the fine-tuning process involves a balance. Too much fine-tuning on a narrow dataset might lead to overfitting, where the model becomes too specific to the training examples and performs poorly on new, unseen data. Striking the right balance is important. PPO includes mechanisms to prevent the model from over-optimizing itself.
Part 1 Summary Architecture
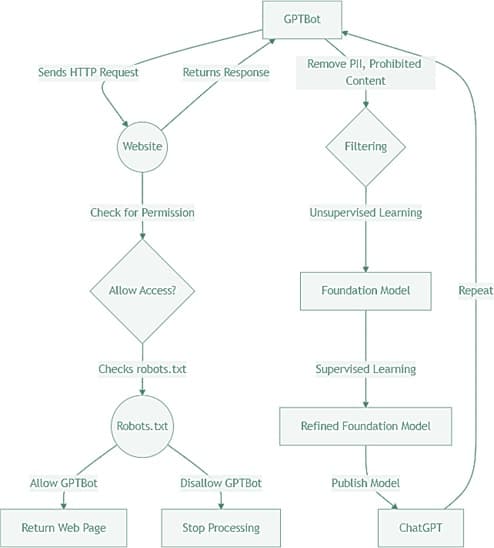
| Step | Description |
|---|---|
| Web Scraping Request | GPTBot sends HTTP requests to scrape data from websites. |
| Permission Check | GPTBot checks the website's robots.txt file for permission. |
| Access Decision | If disallowed, GPTBot stops processing; if allowed, it proceeds. |
| Data Retrieval | If allowed, GPTBot retrieves the website's content. |
| Data Filtering | OpenAI removes Personally Identifiable Information (PII) and prohibited content. |
| Unsupervised Learning | Filtered data is used for unsupervised learning to create a foundation model. |
| Supervised Fine-Tuning | The model is refined with supervised learning using curated datasets. |
| Model Deployment | The final refined model is released as ChatGPT. |
| Continuous Improvement | The process repeats to improve the model and refresh its training data. |
How ChatGPT Works - Part 2
After the LLM is trained and fine-tuned it's ready to use. To illustrate how ChatGPT operates, look at a straightforward example."
Step 1: Text Input
Imagine a user inputs the following partial sentence into ChatGPT.

ChatGPT processes the input text, referred to as a "prompt” because it serves as a prompt that triggers a response from the model. The prompt undergoes some preprocessing steps to handle special characters, whitespace, and other formatting issues. The goal is to ensure that the input text is in a format that the model can understand.
Step 2: Tokenization
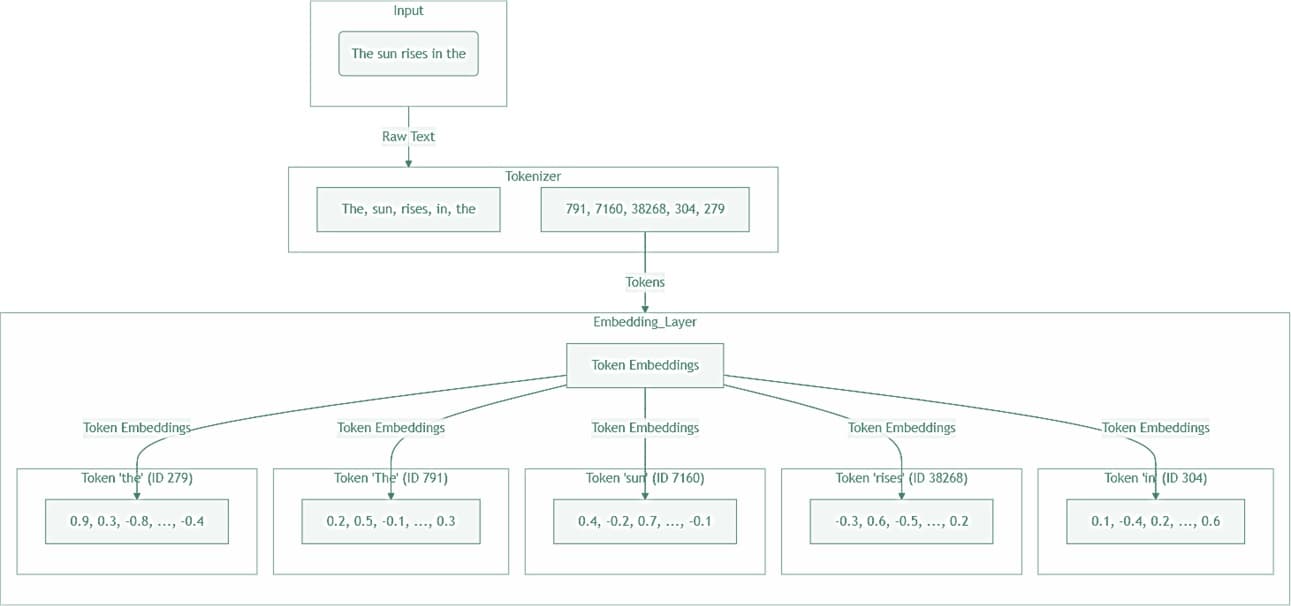
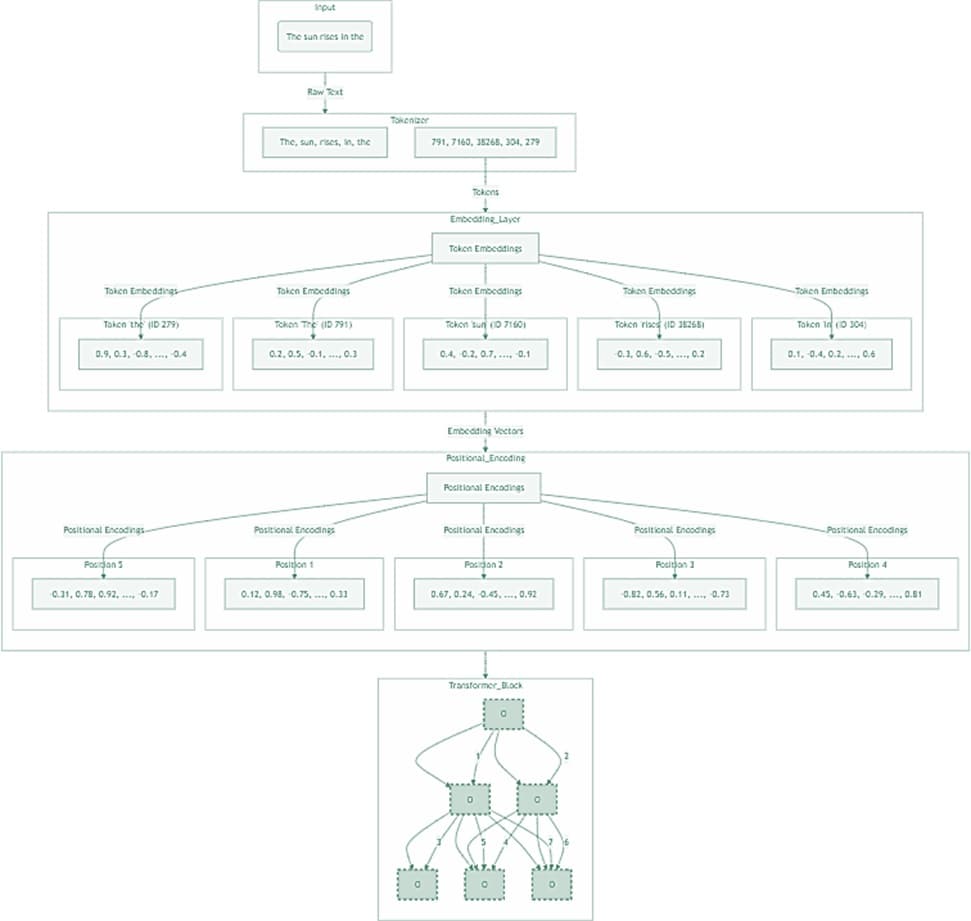
To understand how LLMs work, it's important to understand how they handle words. It begins with a process called tokenization. During tokenization, ChatGPT uses Byte-Level Byte Pair Encoding (BBPE) to break down the input prompt into smaller units called tokens. Tokens can represent entire words or parts of words, each assigned a unique number known as a token ID. This ID serves as its identifier within the model's vocabulary.
For example, during tokenization, the input prompt "The sun rises in the" is split into individual tokens: ["The", " sun", " rises", " in", " the"] and assigned token IDs [791, 7160, 38268, 304, 279].

Step 3: Token Embedding
The token IDs are converted (mapped) into their corresponding vectors, also referred to as word embeddings. These vectors were created during the training process. Instead of storing entire phrases or sentences, the model creates a vector for each token and stores them within the model's vector space.
During training, the model learned to map tokens (words) to their vector representations. Based on the context in which they appear in the training data, the model adjusts the parameters (i.e., the weights associated with each word embedding). This process ensures that vectors are generated such that words with similar meanings or usage have vectors that are close together in the vector space. This is essential for understanding the context of the input. For instance, "sun" might have a vector representation that encodes its characteristics such as sunlight, day, and brightness.
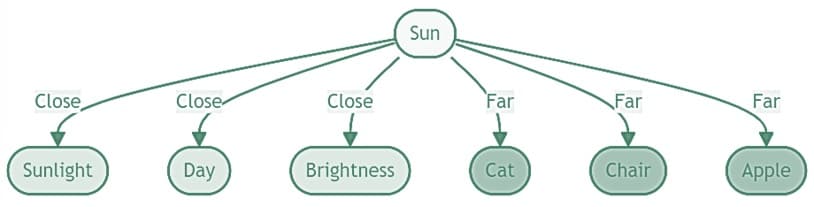
Returning to the example input, after the token IDs [791, 7160, 38268, 304, 279] are passed to the embedding layer, they are converted into vectors. These vectors are high-dimensional and are typically abbreviated in diagrams like the one above for simplicity.
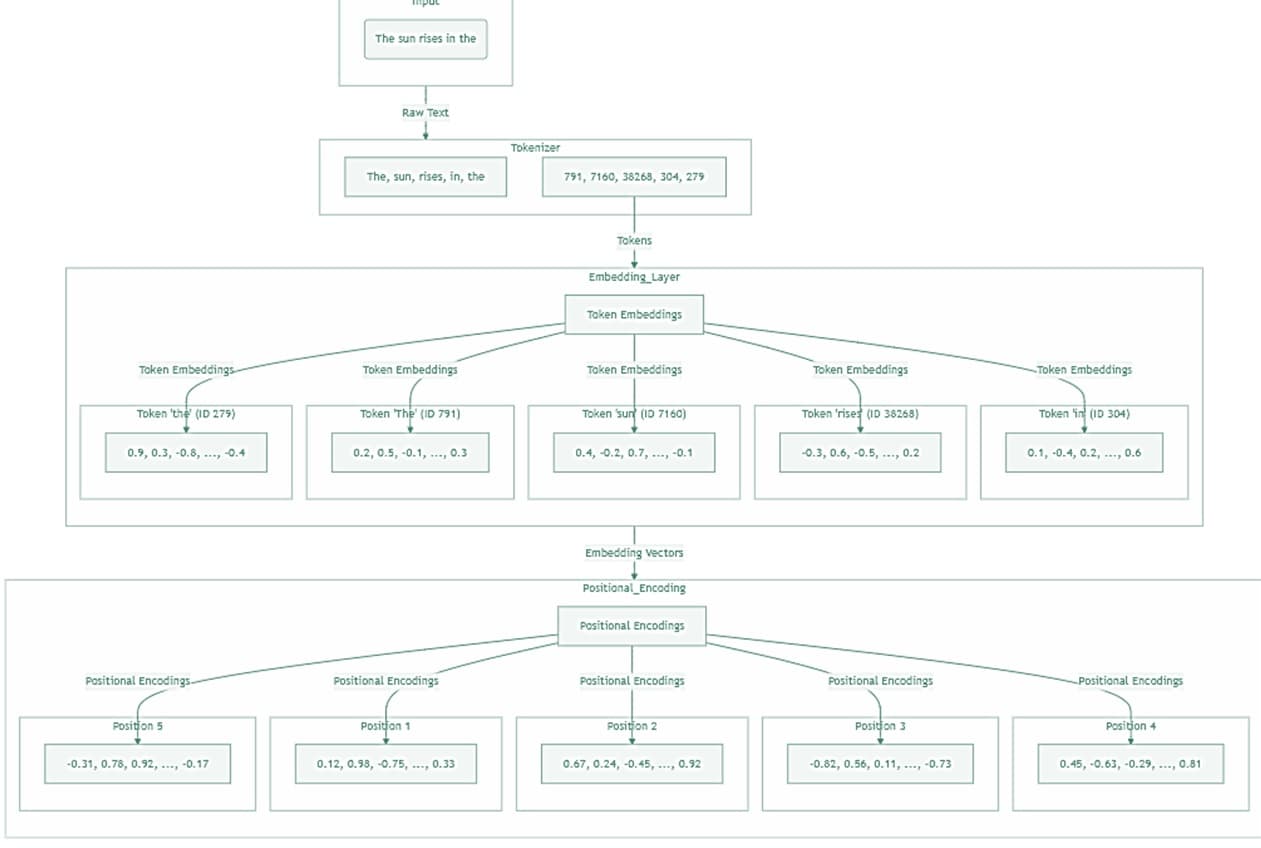
Step 4: Positional Encoding
Before the vectors are fed into the model, they undergo positional encoding. Transformers, which use the attention mechanism, don't inherently understand the order in which words appear in a prompt.
Without positional encoding, the model would perceive the sentence as just a bag of words, with no understanding of their order. Positional encoding assigns a unique representation to each word based on its position. For example, the sentence:

Without positional encoding, the model might see it as:

With positional encoding, the model understands the order of the words:

Positional encoding uses sine and cosine functions of different frequencies to represent positions within a sequence. For a given position 𝑝𝑜𝑠 and dimension 𝑖, the positional encoding is calculated using the following formulas:
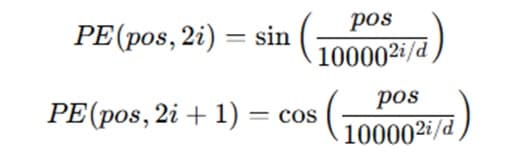
Where 𝑝𝑜𝑠 is the position, 𝑖 is the dimension, and 𝑑 is the total dimension of the embeddings.
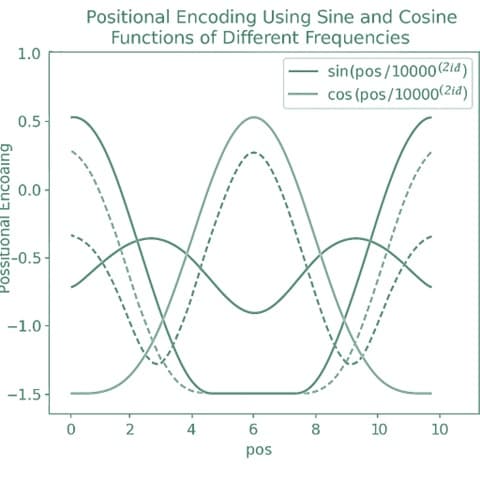
The use of sine and cosine with different frequencies helps ensure that each position has a unique representation, making it easier for the model to capture the relationships between elements in the sequence. The frequencies decrease exponentially as the dimension index 𝑖 increases, creating a smooth and continuous encoding.
In simple terms: Sine and cosine are just ways to help create unique patterns for each item, and by changing their speed, they make sure that each item in the sequence looks different.
Step 6: Multi-layered Transformer
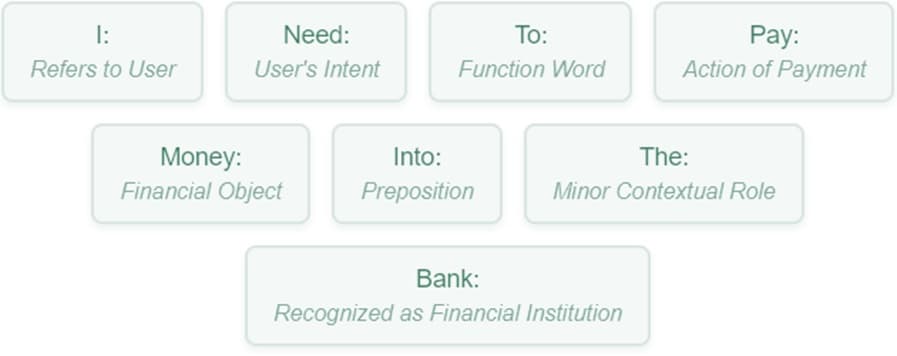
One of the fundamental challenges in AI language processing is deciphering the meaning of words, which often have multiple interpretations depending on context. Take "date," for example. It could mean a specific day on the calendar, or it could refer to a type of fruit. This is called homonymy. Then there's polysemy, where a word has related meanings. Consider the word "bank," which can mean a financial institution or the side of a river.
ChatGPT relies on contextual information to disambiguate between different meanings of a word. This ability to capture contextual information is a key feature of ChatGPT and is achieved using transformer architecture.
So, after the positional encoding stage, the input embeddings with positional encodings are passed through multiple layers of transformer blocks. Each transformer block consists of self-attention mechanisms and feedforward neural networks. The outputs from one transformer block are passed as inputs to the next block, with residual connections helping to mitigate the vanishing gradient problem in deep networks.
For example, let's input the prompt "I need to pay money into the bank":

Self-Attention Mechanism
The input is processed through multiple “attention heads” simultaneously. This self-attention mechanism allows the model to weigh the importance of each token (word) in relation to every other token in the sentence. It helps the model understand the relationships between words, which is key to how LLMs get context.

Feedforward Layers
The information from the self-attention mechanism then goes through feedforward neural networks. These networks consist of layers that apply linear transformations (like matrix multiplications) and activation functions (like ReLU), which helps in refining the information learned from the self-attention step.
The final output from these feedforward layers is a set of scores called logits. Each logit represents the model's estimate of how likely each word in the vocabulary is to be the next word in the sequence.
Transformers are often called 'black boxes' because we don't fully understand how they "make decisions". Since they are self-trained and have hundreds of billions of parameters, it's hard to figure out exactly what each parameter does. Researchers of Explainable AI (XAI) are trying to 'reverse engineer' these models to understand them better.
Step 7: Probability Calculation
A softmax function is then applied to these logits to convert them into probabilities. The softmax equation is used to calculate the actual probability of each token given the context from previous tokens:
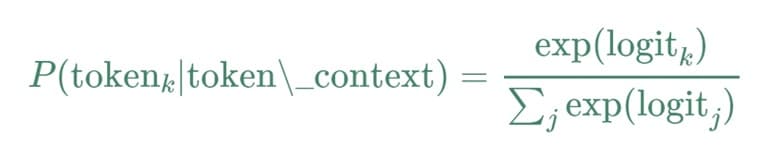
In the formula P(tokenₖ|token\_context) this represents the probability of the next word (tokenₖ) based on the words that came before it (token\_context). The formula Σⱼ exp(logitⱼ) represents the total score for all possible words in the model's vocabulary, which helps determine the probability of each word being chosen.
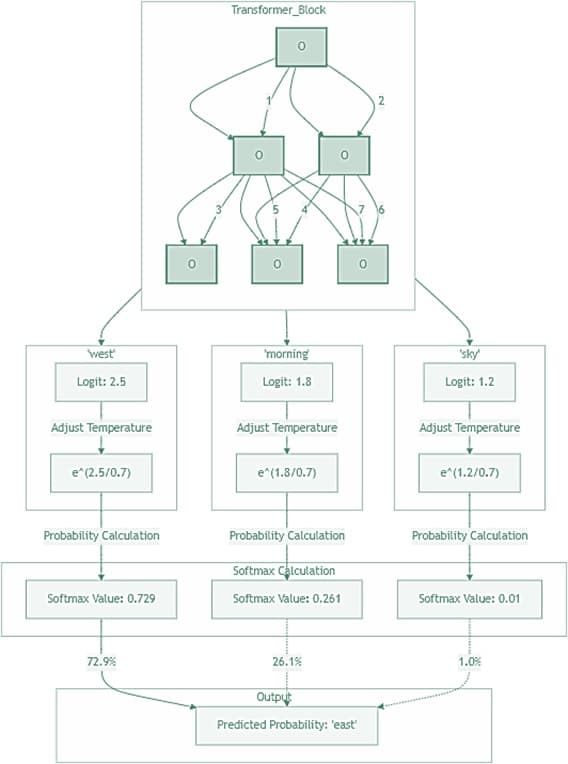
This helps the model decide which token is the most likely the next word. For instance, it might determine the following probabilities:
- ln(0.6) for "East"
- ln(0.3) for "Morning"
- ln(0.1) for "Sky"
In other words, this process helps the model predict the most likely next word. For example:
- "East" → 60% chance
- "Morning" → 30% chance
- "Sky" → 10% chance
ChatGPT generates the next word based on these probabilities. In this example, the highest probability is assigned to the token "east." However, it's important to note that this was a simple example and ChatGPT doesn't necessarily choose the word with the highest probability in a deterministic manner.
Instead, ChatGPT generates words by sampling from probability distributions, adjusting the level of randomness with a "temperature" parameter, and considering context from surrounding words. This keeps responses varied, making them feel more natural. For instance, if "night" was mentioned earlier in the conversation, ChatGPT might have predicted "morning" is the most relevant response to “the sun rises in the”.
After determining the most appropriate words, these predicted tokens are then converted back into text to form a response to the user.
Transformers are autoregressive in the sense that they use their previous outputs to generate subsequent tokens in a sequence. This process involves taking the model's previous “predictions” and feeding them back into the model to help predict the next token. This autoregressive nature is key to how models like ChatGPT generate human-like responses.
So the final output might be:

Part 2 Summary Architecture
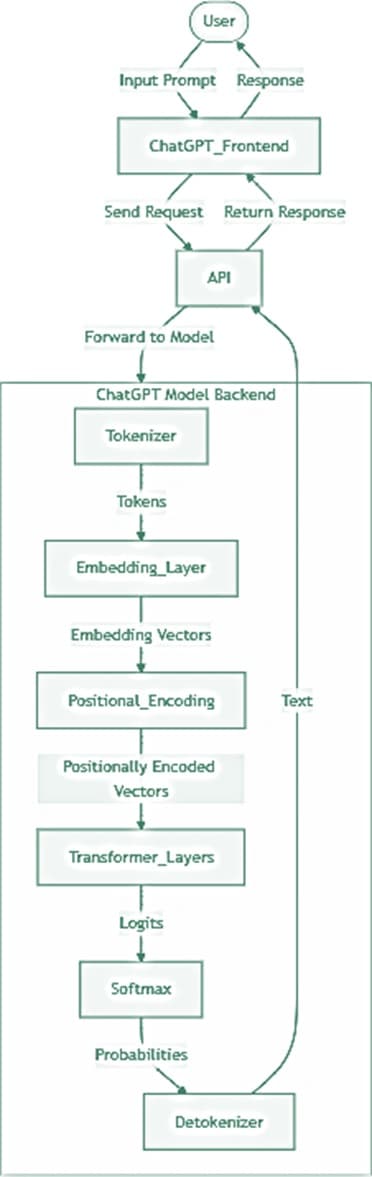
| Step | Description |
|---|---|
| User Input (Frontend) | The user provides an input prompt to the ChatGPT interface. |
| API Request | The prompt is sent to the OpenAI API which forwards it to the ChatGPT backend. |
| Tokenizer | The prompt is first passed through the Tokenizer, which breaks down the text into units called tokens. |
| Embedding Layer | These tokens are then converted into embedding vectors by the Embedding Layer. These vectors are numerical representations that capture semantic information about the tokens. |
| Transformer Layers | The embedding vectors are processed through multiple Transformer Layers. These layers are responsible for understanding the context and relationships between tokens using self-attention mechanisms, which generates the output in the form of logits (probabilities of different possible tokens). |
| Softmax Function | The logits are converted into probabilities by the Softmax function, and the Token Selection process determines which tokens to choose as the final output. |
| Detokenizer | The selected tokens are converted back into text by the Detokenizer. |
| API Response | The generated output from the model is sent back to the API. |
| Display Response | The API returns the output to the ChatGPT interface, which then displays the response to the user. |